之前在 Spark学习笔记之调度 就已经大致描述了应用程序的调度。现在就再详细的剖析下这个过程。
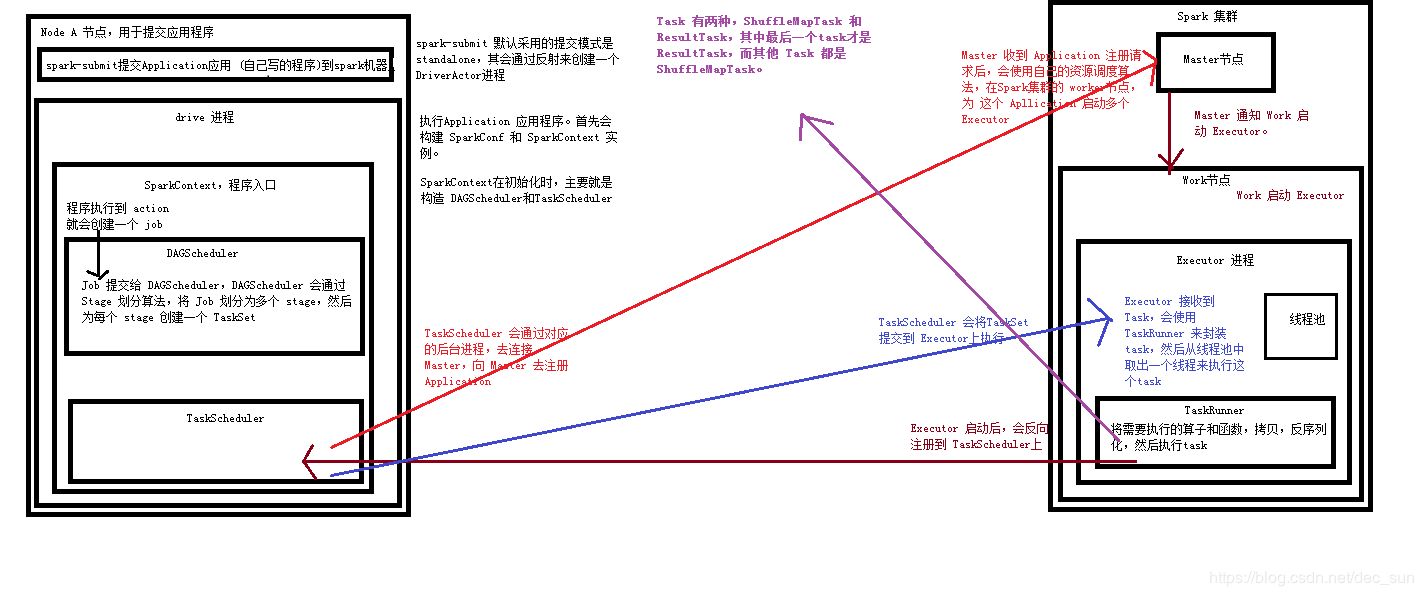
如图所示:Application 通过 submit 被提交到机器上后,该节点会启动一个 Driver 进程。
- Driver 来开始执行 Application 应用程序,首先会初始化 SparkContext,实例化SparkContext;
- SparkContext 实例化后,就会构建 DAGScheduler 和 TaskScheduler;
- TaskScheduler 会通过对应的后台进程去连接 master,向 Mater 注册 Application 应用;
- Master 收到 Application 注册请求后,会通过资源调度算法,在 worker 节点上为这个 Application 应用启动多个 Executor;
- Executor 启动之后,会向 TaskScheduler 反向注册上去;
- 当所有 Executor 都反向注册到 Driver 后,Driver 会结束初始化 SparkContext;
上述流程基本上就完成了资源的分配,接下来就开始实际执行 Application 中的任务了。
- 当应用程序执行到 action 时,就会创建一个 job,并将 job 提交给 DAGScheduler;
job 是 Application 应用程序所有任务的集合 - DAGScheduler 的作用就是:将 job 划分为多个 Stage,并为每个 stage 创建 TaskSet;
- TaskScheduler 会将 TaskSet 中的 Task 提交到 Executor 上去执行;
- Executor 接收到 task后,会使用 TaskRunner 来封装 Task,然后从线程池中取出一个线程来执行这个 Task;
- 每个 Task 针对一个 Partition来执行 Application程序的算子和函数,直到所有操作执行完成。
这里需要注意的是:
DAGScheduler 的 stage 划分算法是通过反向划分的方式来处理,从 action开始作为 final stage,也就是 ResultTask,逆向反推,如果是窄依赖,那么就可以将其划分为一个 stage 内,如果遇到 shuffle 依赖,则将作为第二个 stage 的开始,继续逆向推导。遇到 shuffle 依赖就会生成一个新的 stage,遇到窄依赖就将其划到当前的 stage 中。其中最后一个 stage 称为 ResultTask,其他 stage 称为 ShuffleMapTask。