先看图,总览一下:
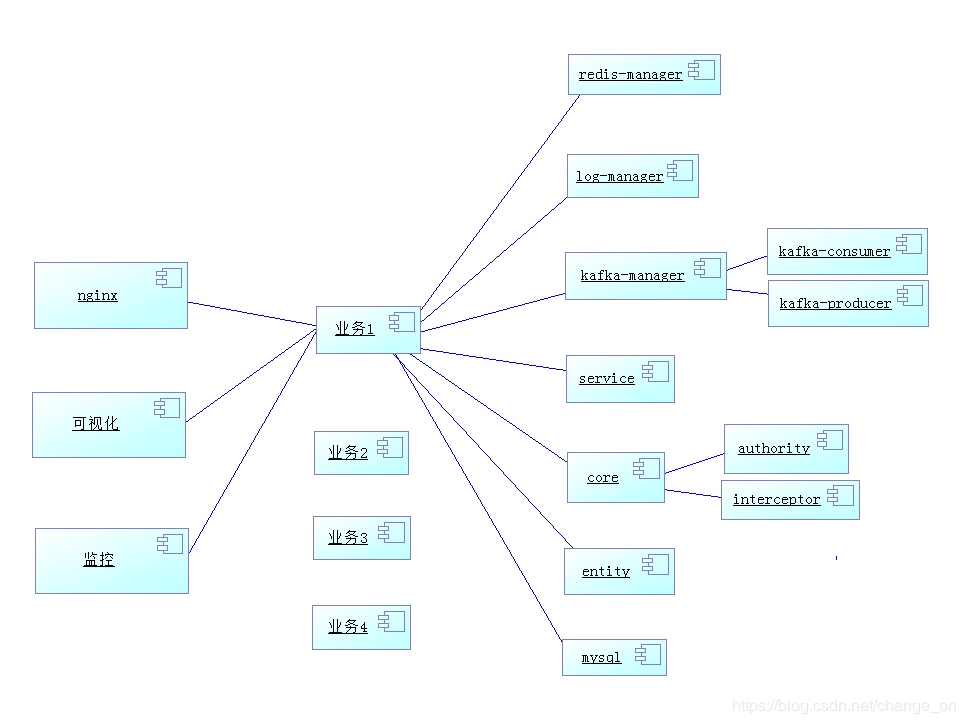
上图的架构是这几个月来开发的总结,照一列一列来看,从右到左
先看右边两列,可归为一类,这一部分可以叫做依赖,作为公共部分。在设计架构之时,要先考虑每一个组件的应用框架,把这些框架的基本部分写好,封装成依赖包,给业务系统调用。这些基础的部分包括以下:
- 缓存:redis redis的地址、端口、线程配置从配置文件读取,把redis的连接释放都做成工具,只提供使用接口
- 日志:推荐用log4j
- 消息中间件:kafka集群,封装工厂配置、提供生产者、消费者接口
- core:权限认证、拦截检查
- 文件系统:ftp/fdfs,管理文件,提供上传下载接口
- 数据库: mysql
- 持久层框架用的mybatis:service提供接口
- 工具类:base64、map、email…
右边第三列作为业务,根据需求,垂直切分业务,对外提供接口的做一个业务子系统、逻辑处理的作为一个子系统、底层运算作为一个子系统,中间通过kafka通信。那么这里就涉及到一个问题,部署的时候,每个业务子系统要配多少台机器,才能达到最佳的处理效果:
- 单台机器:在接收kafka的地方做一个线程控制,允许单台机器在资源耗尽的情况下跑最大线程
- 部署:推荐先各自部署一台,压力测试后,打印出cpu、jvm、文件写入写出的利用率的曲线图,对利用率大的增加机器,最好让各自的资源都跑满(85%以上)
最左边的一列,对对外的
- nginx做负载均衡
- 可视化可以查找内部任务
- 监控系统会监控哪些服务器宕机
以上都是设计方面,还有像数据库读写分离、CDN之类的就不说了。下面是针对更细致的代码层面。对外只有一个业务,对内的大部分是纯后端代码,基于java实现,强烈推荐两本书《thinking in java》和《effective java》,一些不以为然的习惯在高并发下的影响太大了!!!
我分享几点编码技巧:
- 多线程的地方使用线程池,尽量不要new一个线程
- 对象的创建放在循环外,创建的越少越好
- 重复的代码考虑用常用的设计模式,单例、适配器…;.
- Integer 替代int
- 多看书,书到用时方恨少